설명
- 항목들의 순서를 결정하기 위해 집합에 각 항목이 몇 개씩 있는지 세는 작업을 하여, 선형 시간에 정렬하는 효율적인 알고리즘
- 제한 사항
- 정수나 정수로 표현할 수 있는 자료에 대해서만 적용 가능
- 각 항목의 발생 횟수를 기록하기 위해, 정수 항목으로 인덱스 되는 카운트들의 배열을 사용
- 카운트들을 위한 충분한 공간을 할당하려면 집합 내의 가장 큰 정수를 알아야 함
- 시간 복잡도
- $O(n+k)$ : n은 리스트의 길이, k는 정수의 최대값
예시
- [0, 4, 1, 3, 1, 2, 4, 1]을 카운팅 정렬하는 과정
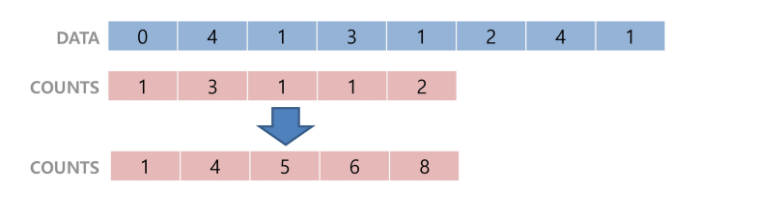
- 1단계: Data에서 각 항목들의 발생 횟수를 세고, 정수 항목들로 직접 인덱스 되는 카운트 배열 counts에 저장

- 2단계: 정렬된 집합에서 각 항목의 앞에 위치할 항목의 개수를 반영하기 위해 counts의 원소를 조정
(counts의 누적횟수 집계)
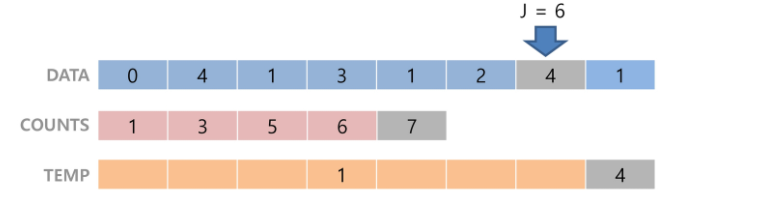
- 3단계: Data의 끝에 위치한 원소의 counts를 감소시키며 재배열
(안정화 정렬을 위해 끝에서 부터 시작)
- counts[1]을 감소시키고 Temp에 1을 삽입

- counts[4]를 감소시키고 Temp에 4를 삽입
- 같은 방법으로 Temp 리스트가 완료할 때까지 반복 ...
- 마지막 counts[0]을 감소시키고 temp에 0을 삽입

- Temp 업데이트를 완료하고 정렬 작업을 종료
- 배열을 활용한 버블 정렬
- 앞선 과정을 코드로 구현하면 아래와 같다.
arr = [0, 4, 1, 3, 1, 2, 4, 1]
cnt_list = [0] * (max(arr)+1)
result = [0] * len(arr)
for i in range(0, len(arr)):
cnt_list[arr[i]] += 1
for i in range(1, len(cnt_list)):
cnt_list[i] += cnt_list[i-1]
for i in range(len(arr)-1, -1, -1):
result[cnt_list[arr[i]]-1] = arr[i]
cnt_list[arr[i]] -= 1'Algorithm' 카테고리의 다른 글
| Delta Search (델타 탐색) (0) | 2021.02.15 |
|---|---|
| 2-dimensional array iteration methods (2차원 배열 순회 방법 ) (2) | 2021.02.15 |
| Greedy Algorithm (탐욕 알고리즘) (0) | 2021.02.09 |
| Exhaustive Search (완전 검색) (0) | 2021.02.09 |
| Bubble-sort (버블 정렬) (0) | 2021.02.08 |